# HTTP 버전별 정리
웹을 한다고 깝죽거리고 있는데 HTTP가 뭐하는건지 아직도 잘 모르고 있는 느낌이다.
그러다가 HTTP 3에 대해서 글을 읽어봤는데 내가 HTTP프로토콜에 대해서 알고 있는게 없는 느낌이 들었다. HTTP 코드나 명세만 잘 알면 되지 않을까 싶기도 했는데 많이 쓰던 HTTP 1.1에서 2으로 올라갈때도 거진 속도가 2배 향상되는걸 보고(환경마다 다르다. 레이턴시가 더 안좋은 상황에서 효과를 많이 볼 수 있다고 함) 어떻게 발전되는지랑 각 명세에 대해서 뭐가 더 업그레이드 돼서 올라갈지 말지 알 것 같다.
모르면 올라갈수도 내려갈수도 없다. 그냥 지금 동작한다는 상태에서 만족하고 있을수밖에 없는 느낌
# HTTP 기본
일단 HTTP는 웹에서 리소스들을 가져올때 사용되는 프로토콜이다. 모든 데이터들 교환의 근간이고 클라이언트-서버 프로토콜이다.
클라이언트-서버 프로토콜은 수신자 측, 클라이언트측에 의해 요청이 초기화되는 프로토콜을 말한다고 한다.
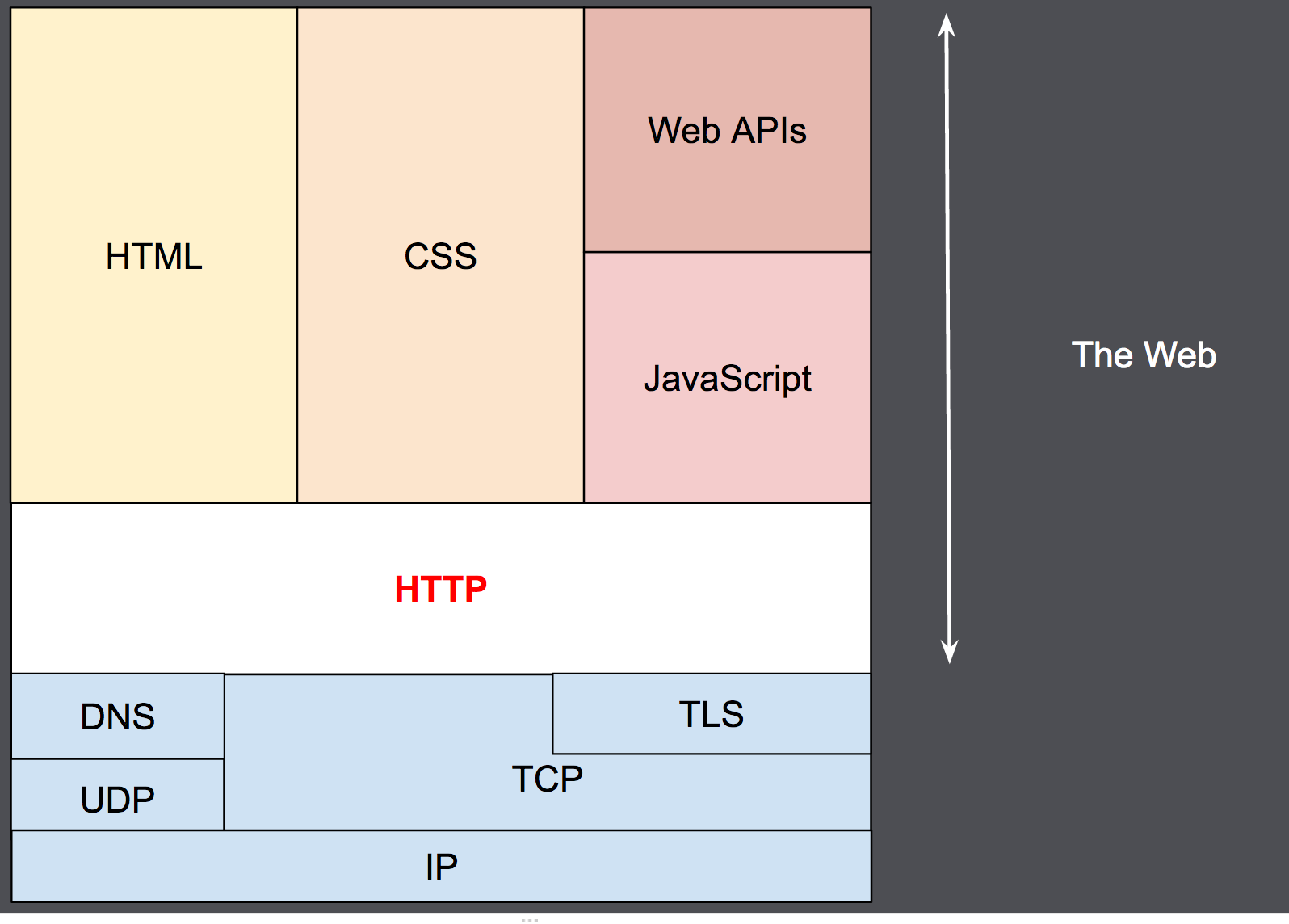
이미지 한장으로 설명되는 HTTP 구조.
IP프로토콜 위에 UDP랑 TCP가 올라가있고, 그 위에 DNS랑 TLS가 올라가있고 그 위에 HTTP가 올라가있다. 이 HTTP로 HTML, CSS, JS가 올라가고 JS로 web api랑 통신을 이리저리 해서 데이터를 주고받는 구조로 설명이 된다. 요 HTTP 위가 웹개발자들이 주로 접근해서 사용하는 것들이고, 아래에서는 뭐.. 만들어놓은거 위에서 잘 돌아가기는 하니까 한번도 본적도 없는것 같다.
아무튼 이 HTTP로 제어할수 있는 일반적인 것들은 캐시, origin(브라우저에서 동일한 origin으로부터 온 페이지만이 웹페이징의 전체 정보에 접근할 수 있음→ HTTP헤더에서 CORS설정으로 완화 가능), 인증, 프록시, 터널링, 세션이 있다.
또 HTTP 1.0에서는 각 요청/응답에 대해서 별도의 TCP연결을 열었지만, HTTP 1.1에서는 파이프라이닝 개념과 지속적 연결의 개념을 도입하고 HTTP/2에서는 연결을 더 지속적이고 효율적으로 유지하는데 도움을 주기 위해서 단일 연결 상에서 메세지를 다중연결(multiplex)의 개념이 도입되었다.
# HTTP 흐름
클라이언트가 서버랑 통신하려고 할때, 연결과 데이터 송수신 흐름은 다음과 같다.
1. TCP 연결 수립: 클라이언트는 새 연결을 열거나, 기존 연결을 재사용하거나 해서 서버에 대한 여러 TCP연결을 열 수 있음.
2. HTTP메세지 전송. HTTP 헤더는 2.0 이전에서는 사람이 읽을수 있는 평문으로 보내지지만(TLS적용이 되지 않다면), HTTP/2에서는 프레임속으로 캡슐화된다.
https://datatracker.ietf.org/doc/html/rfc7541
의 Introduction에 보면,
In HTTP/1.1 (see [RFC7230]), header fields are not compressed. As web pages have grown to require dozens to hundreds of requests, the redundant header fields in these requests unnecessarily consume
bandwidth, measurably increasing latency.
라고 한다. 헤더가 압축되지 않음으로 불필요한 데이터 전송을 하고 있다는 것이다. HTTP/2에서 헤더는 HPACK이라는걸로 인코딩 된다.
3. 서버는 전송받은 요청에 대해서 처리하고, 요청에 대한 응답을 보내준다. 클라이언트측에서는 서버에서 전송받은 응답을 읽어들이고, 응답을 활용해서 뭔가를 한다.
4. 연결을 닫거나 다른 요청을 위해서 재사용한다.
HTTP/1.1에서 도입된 파이프라이닝이 활성화되면 첫번째 응답을 완전히 수신할때까지 기다리지 않고 여러 요청을 보낼 수 있다.
# HTTP 헤더 실물
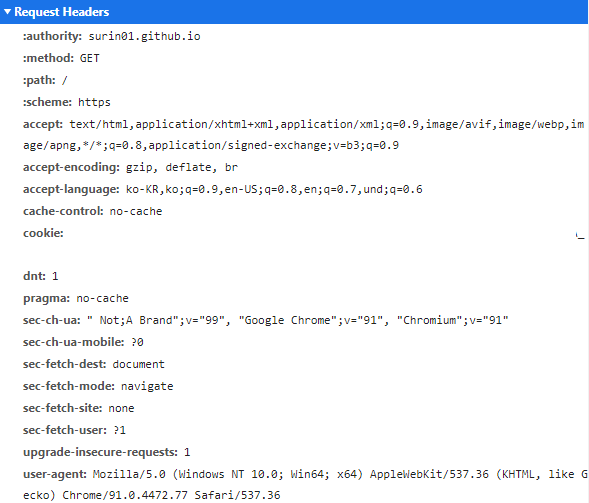
블로그 페이지 요청을 크롬 개발자도구로 본 모습이다.(cookie 부분은 지웠다) method가 :method:로 뜨는걸로 봐서는 HTTP/2를 사용중인것 같다(HTTP/1.1을 사용하면 아래의 사진과 같이 나온다)
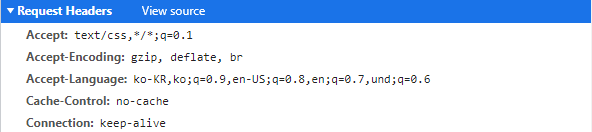
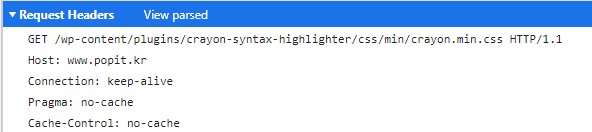
(같은 요청의 헤더이고, 파싱된 데이터에서는 Method가 아에 나오지 않고 소스로 봐야 GET이라고 나온다. 이는 https://developers.google.com/web/fundamentals/performance/http2?hl=ko에서 모든 헤더 필드 이름은 소문자이고 요청 줄이 개별적인 :method, :scheme, :authority및 :path 유사 헤드 필드로 분할된다는 구문에서 볼때에 근거하여서 이다.)
위의 헤더에서 cache-control은 개발자 도구에서 cache 사용을 꺼놔서 추가되는 헤더같도, 주로 보게 될 것은authority, method, accept, accept-encoding, accept-language, cookie정도일것 같다.
user-agent는 구버전 브라우저들 html이나 js에서 구버전 브라우저 지원할때 사용하거나 봇 만들어서 수집하는거 접근 거부하기 위해서 사용하기도 한다...라고 알고 있다.
nodejs에서 개발하다보면 request에서 cache라던가 라우팅할때 method등에 대해서 접근해서 사용한 기억이 있다.
# HTTP 버전이 올라가면서 달라지는 것들
### 최초의 HTTP 프로토콜
최초에 있었던 HTTP는 버전이 아에 없었다. 극히 단순한 형태의 요청으로 단일 라인으로 구성되어 있고, GET 메소드만이 사용가능했고 HTML파일만 전소될 수 있었다. 상태, 오류코드도 없고 에러가 발생할 경우에 특정 HTML파일이 사람이 처리할 수 있도록 해당 파일에 문제에 대한 설명과 함께 보내졌다.
이 버전은 후에 나오는 프로토콜과 구분하기 위해서 HTTP/0.9라고 불려지거나 원-라인 프로토콜이라고도 불려진다.
### HTTP/1.0
HTTP/1.0의 키워드는 확장성, 융통성이라고 할 수 있을것 같다. 버전 정보가 각 요청과 함께 전송되기 시작했으며, 상태 코드 라인 또한 응답의 시작부분에 붙어 전송되었으며 브라우저가 요청에 대한 성공과 실패를 알 수 있게 되었다. HTTP 헤더 개념은 요청과 응답 모두를 위해 도입되었고, 메타데이터 전송과 Content-Type을 통해서 HTML파일 이외의 문서를 전송하는 기능이 추가되었다.
-Request, Response
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
A page with an image

-html 파일 안에 위치한 gif파일을 처리하기 위한 추가적 요청과 응답
GET /myimage.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/gif
(image content)
https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP 에서 발췌
최초버전보다는 확실히 복잡해졌다.
### HTTP/1.1
1.1버전은 1.0이 나온지 몇 달 안되서 1997년 초에 공개되었다. 이전에 있었던 모호한 명세들을 명확하게 하고 많은 개선 사항을 도입하였다.
- 커넥션 재사용
- 파이프라이닝 추가
- 청크된 응답 지원
- 캐시 제어 메커니즘 도입
- 언어, 인코딩 혹은 타입을 포함한 컨텐츠 네고시에이션 도입
- Host 헤더 도입을 통한 동일 IP주소에 다른 호스트를 하는 기능인 서버 코로케이션 가능
-서비스에서의 서버 호스팅과 코로케이션의 차이?
서버 호스팅은 서버, 회선, 공간 모두를 임대하여 위탁 관리를 맡기지만, 코로케이션은 IDC내에 고객이 소유하고 있던 서버를 입주시키고 위탁 관리를 맏긴다는 차이가 있다. 기능에서의 코로케이션과 서비스에서의 코로케이션의 차이가 있는 이유는 IDC에 관리위탁을 맡길 때에 다중의 IP를 확보하고 있기 때문에 서버별 개별 IP가 들어갈수 있기 때문에 한 IP로 다중의 서버를 운용할 수 있는 기능에서의 코로케이션 구별해야 할 것 같다.
HTTP 1.1 버전이 출시되고 난 후 15년간 여러 방면으로 확장되었고, Method가 GET, POST, PUT, DELETE, HEAD, OPTIONS, TRACE, PATCH로 확장되고 브라우저 갱신 없는 브라우징을 가능하게 하는 API, SSL과 SSL의 보안취약점으로 인해 나오게된 TLS등등이 나오게 되었다.
### HTTP/2
HTTP/2의 키워드는 성능이라고 할 수 있겠다.
웹의 시장이 커지고 제한된 대역폭에서 서버가 처리해야 할 것들이 많아지면서, 프로토콜의 성능에 대한 기능 개선이 필요해지게 되었다. 2010년 전반기 google에서 SPDY 프로토콜 구현으로 클라이언트-서버 간의 데이터 교환을 대체할 수단을 실증하였고 HTTP/2의 기초로 기여하였다.
HTTP/2프로토콜은 이전 1.1버전과 다른 몇가지 근본적 차이점을 가지고 있는데,
- 텍스트 프로토콜이 아니라 이진 프로토콜
- 병렬 요청이 동일한 커넥션 상에서 이루어질 수 있는 다중화 프로토콜
- 전송된 데이터의 중복과 그러한 데이터로부터 발생하는 오버헤드 제거
- 서버 푸쉬라는 기능이 나옴. 클라이언트가 HTML문서를 요청하고 요청 HTML에 css, image등이 포함되어 있을때 이전 1.1에서는 클라이언트가 요청한 HTML문서를 수신한 후 HTML문서를 해석하면서 필요한 리소스를 재 요청하는 반면에 HTML/2에서는 server push라는 기법을 통해서 클라이언트가 요청하지 않은 리소스들, html파일에서 필요한 css, js, image등의 리소스를 푸쉬해주는 방법으로 클라이언트의 요청을 최소화해서 성능 향상을 이끌어내는 것. 이를 PUSH_PROMISE라고 부르며 PUSH_PROMISE를 통해서 서버가 전송한 리소스에 대해서는 클라이언트가 요청을 하지 않는다.
HTTP/2의 설명을 보면,
HTTP/2 is a replacement for how HTTP is expressed “on the wire.” It is not a ground-up rewrite of the protocol; HTTP methods, status codes and semantics are the same, and it should be possible to use the same APIs as HTTP/1.x (possibly with some small additions) to represent the protocol.(https://http2.github.io/)
http 프로토콜을 완전히 재작성 하는것이 아니라, 표현 방법을 바꾸는 것이다. 내 식대로 표현하자면 서순을 바꿨다고 할 수 있을 것 같다.
기존의 프로토콜이 있던걸 성능 향상을 위해서 바꿨다는 것이다.
구동하던 웹 서버, API 등에서 1.1 버전의 프로토콜으로 돌고 있을 것이고, 2.0으로 업그레이드 하기 위해서 약간의 수정으로 대체할 수 있을것이고, 개발 의도에도 그렇게 말하고 있다. 그 증거로 15년 5월에 공식적으로 표준화되었고 지금모든 사이트중의 45.5퍼센트가 HTTP/2를 사용하고 있다고 한다(https://w3techs.com/technologies/details/ce-http2)
### HTTP/3?
이전의 1.1, 2버전들은 기본적으로 TCP를 통해서 통신을 구현하는 방법으로 구현되어 있다. TCP라 하면 데이터의 신뢰성이 보장된다 라는걸 깔고 가기 때문에 웹 컨텐츠들 전송할때 TCP가 국룰로 생각하고 있었는데, QUIC이라는 프로토콜이 등장하면서 바뀌게 된다. 이 포스팅을 적는 것도 내가 알던 이런 기존의 내용에 대해서 바뀌는 포인트여서 적게 된 것 이기도 하다.일단 QUIC은 UDP위에서 돌아가는 프로토콜이다.
기존에 잘 돌던 TCP를 냅두고 왜 UDP를 쓰는가 하니까 결론부터 말하자면 기존 TCP는 너무 오래되고 시간이 지나면서 온갖 좋은 기능이란 기능을 다 때려박은 무거운 라이브러리가 된거고, UDP는 필요한 기능만 들어가있는 가벼운 라이브러리라는 것이다.
TCP와 TUDP의 헤더를 살펴보자면,


그냥 뭐 휑하다. 헤더의 사이즈를 무한정 할당할수가 없기 때문에 옵션을 포함해서 헤더의 크기는 최대 60 Bytes인데, 기본 헤더의 크기만 20 Bytes이고 옵션이 최대가 40 Bytes바이트인데, 여기에 또 MSS Option, WIndow-Sacling Option, Timestamp Option, Selective Acknowledgement Option 등등이 들어간다. TCP에 대해서 소개하는 글이 아니니까 여기까지만 말하고, 그만큼 TCP에 많은 옵션들이 있고 더이상 뭔가를 집어넣기에는 프로토콜이 너무 무겁다는 것만 짚고 넘어가면 되겠다.
아무튼 이러한 상황 속에 UDP의 헤더 속 디폴트는 사용안함으로 되어 있는 체크섬을 활성화 시켜주고, 흐름 제어도 되지 않는 UDP를 어떻게 또 잘 지지고 볶아서 TCP와 비슷한 수준의 신뢰성을 가지고, TCP보다 빠른 레이턴시를 가지는 것이 QUIC의 목적이다.
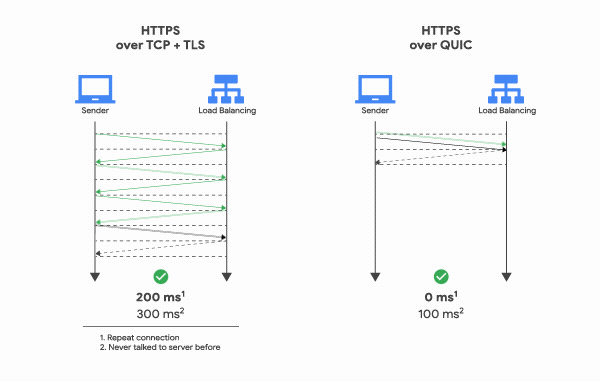
HTTP 2 이하에서는 연결시 TCP를 사용하기 때문에 3Way Handsake가 필수적이다(SYN, SYN ACK, ACK로 이어지는 바로 그것)이 일련의 과정을 1RTT(Round Trip Time)이라고 하는데, 극적인 차이를 위해서 HTTPS가 tcp와 tls를 이용해서 통신하는 것과 QUIC을 이용해서 통신하는 것의 차이점을 보자. 좌측의 TCP와 TLS를 이용할 떄에는 일단 연결에만 1RTT, TLS를 위해 1RTT, TLS를 사용한 암호화를 위해 TLS의 자체 핸드쉐이크까지 총 3RTT가 필요하다.
하지만 QUIC은 그냥 첫 요청때 모든 필요한 데이터를 다 때려넣고 한방에 요청을 하고, 서버는(위 그림에서는 로드벨런서가 있고 그 밑에 서버가 있겠지만) 요청에 응답하면 연결 수립이 끝난다. 그리고 TLS를 이용하여서 서로 자신의 세션 키를 주고받아 암호화된 연결을 성립하고 나서 세션키와 데이터를 교환할수 있지만, QUIC은 서로의 세션 키를 교환하기 전에 데이터 교환을 할 수 있기 때문에 연결이 빠르게 되는 것이다.
첫 교환때는 서버의 세션 키를 모르는 상태이기 때문에 클라이언트가 선택한 Connection ID를 통해서 생성된 특별한 키인 초기화 키를 사용하여 통신을 암호화한다. 이렇게 한번 연결에 성공했다면 서버는 그 설정을 캐싱해놓고 있다가 다음 연결 때는 캐싱해놓은 설정을 사용하여 바로 연결을 성립하기 때문에 0RTT로 바로 통신을 시작할 수 있다.
또한 이 Connection ID를 사용하여 클라이언트의 IP주소가 변하는 경우(예를 들어서 와이파이 환경에서 셀룰러 환경으로 변경될 때 등) 기존에 진행되고 있던 다운로드 등을 계속할수 있게 되는 것이다
(https://http3-explained.haxx.se/en/quic/quic-connections).
# 결론
새롭게 등장하고 있는 HTTP/3은 기존의 HTTP/2에서 도입된 멀티플렉싱과 같은 장점들은 그대로 가져가면서, Connection ID와 같이 IP와 관계없이 연결이 유지된된다건가, 패킷 손실 감지에 걸리는 시간을 감축시키는 등 더 나은 방향으로 발전한다. 기술 스펙만 듣고 나면 무조건 이득이고 꼭 채용해야하는 기술같아 보인다.
하지만 모든 기술에 이득이 있으면 실도 있는게 맞지 않나 한다. UDP로 TCP급의 신뢰성을 구현하다가 나오는 문제점이 있을수도 있고, 실제 사용될때에 발견될 수 있는 문제점 들도 있을 것이다.
그래도 이전에 내가 가지고 있던 고정관념인 신뢰성이 필요한 데이터는 무조건 TCP, 그냥 흘러가는 데이터는 UDP라는 걸 깨주고 어떤 기술이든 사용하기 나름이라는 생각을 가지게 해주는 공부였다.