graphQL?
graphQL(이하 gql)은 쿼리 언어이자 api를 위한 서버측 런타임이다. 클라이언트에서 “요청한 만큼”의 데이터를 제공하는데 우선 순위를 둔다. 이전 RESTapi에서 리소스에 대한 형태 정의와 데이터 요청 방법이 하나로 합쳐져서 클라이언트가 서버측에 대해서 데이터를 요청하고 받아왔지만, gql에서는 리소스에 대한 형태 정의와 데이터 요청이 분리되어 있다.
즉, 이전 RESTapi에서는 규약에 맞춘 api의 엔드포인트에 요청을 보내면 사전에 서버측 정의된 형태대로 데이터가 날라왔고, 이에 대해서 클라이언트가 해석하고 사용하는 방법으로 데이터가 처리된다. 반면에 gql에서는 단일 엔드포인트만 존재하고(필요한 경우 복수의 엔드포인트를 생성할 수 있다.), 필요한 정보의 구조와 크기를 요청시 클라이언트단에서 결정하고 gql에서는 리소스에 대한 정보만 정의해놓는다.
그렇기 때문에 이전 REST에서 메소드가 작업의 유형을, URI가 리소스를 나타냈지만, gql에서는 schema가 리소스를 나타내고 Query, Mutation 타입이 작업의 유형을 나타게 된다.
이러한 사유로 REST에서 여러 리소스에 접근하기 위해서는 여러번의 요청이 필요하고, gql에서는 단일 요청으로 여러 리소스에 접근하여 네트워크의 부하와 필요 데이터를 모으는데 필요한 레이턴시를 줄일 수 있다.
현재 Nest.js를 사용하여 개발을 진행하고 있지만, gql에 대한 기반 지식이 없기 때문에 조금 더 근본적인 내용 위주로 공부하고 적어 볼려고 한다.
그럼 gql은 만능인가?
단연코 아니다. 모든 기술에도 적용되는 말이기도 하지만, 어떠한 기술이라도 단점없이 사용할 수 있는 만능키가 되지는 않는다. 장점이 있다면 단점도 있기 마련. 단점에 대해서도 알아보고 이 기술을 접목시켜야 하는지, 아니면 그렇지 않아도 되는지에 대해서 생각해보고 적용하도록 하자.
단점 1. HTTP 캐싱
이전 RESTapi에서는 다른 엔드포인트를 사용하고, HTTP의 캐싱 전략은 URL에 각자의 정책을 설정하고 엔드포인트별 캐싱이 이루어지게 된다. 그렇기 때문에 RESTapi는 이러한 캐싱 전략을 그대로 따라가서 캐싱을 다른 기술 없이도 편하게 사용할 수 있게 되고, 대량의 데이터를 가져오는 get의 경우에 성능상의 우위를 가질 수 있게 된다. 하지만 gql은 단일 엔드포인트를 가지기 때문에 이러한 캐싱 전략을 그대로 가져가기 힘들고, gql만의 캐싱 전략을 구축해야 한다. 이때 자주 쓰이는 것이 영속 쿼리, 아폴로 엔진 등이 있다.
먼저 영속 쿼리에 대해서 알아보자면, 자주 사용하는 쿼리에 대해서 해쉬 또는 ID로 묶어주고, 이 해쉬/ID를 클라이언트에게 보냄으로써 클라이언트는 필요 쿼리를 직접 생성하고 서버측으로 보내주는 것이 아니라, 이 해쉬값/ID를 서버로 보냄으로써 서버는 해당 해쉬/ID를 해쉬맵에서 찾고 그에 대응하는 쿼리를 사용하여 클라이언트의 요청을 실행하게 된다. 이때 해쉬를 사용하여 해당 쿼리에 대한 결과값을 캐싱하여 사용할 수 있을 것이다.
두번째로 아폴로 엔진을 사용한 캐싱이 있다. 이 또한도 영속쿼리와 비슷한데, 잘 설명이 되어있는 그림이 있다.
출처
이전의 persistedQuery, 영속 쿼리와 비슷한 매커니즘이다. 하지만 일련의 작업들을 아폴로 엔진이라는 프로그램이 처리해주게 된다.
단점 2. 서버와 클라이언트의 스키마 공유
기존 RESTapi를 사용할 때는 클라이언트가 데이터베이스 스키마를 알 필요가 없었다. 미리 지정된 엔드포인트로 요청을 보내면 api 명세 문서대로 지정된 구조의 결과가 날라왔고, 이 데이터를 클라이언트 단에서 사용하기만 하면 되는 형태였다. 하지만 gql을 사용하게 되면 api문서가 따로 없고, 스키마가 서버사이드에 있기 때문에 이러한 스키마 파일을 클라이언트에게 공유할 방법이 필요하게 된다.
대부분 graphiql과 apollo devtools를 이용해서 서버가 graphql url을 열어주면 클라이언트가 해당 URL에 접속해 직접 스키마를 보고 쿼리를 작성해보고, 코드에 반영하게 된다.
단점 3. 클라이언트 개발자에게 전적인 권한 위임
기존 RESTapi를 사용할 때에는 클라이언트가 어떠한 리소스를 사용할지에 따라 요청을 보낼 URL만 지정하면 됐었다. 하지만 gql을 사용함에 따라 클라이언트가 자신이 쓸 리소스의 스키마를 작성하고 요청을 보내게 됨으로, 클라이언트 개발자가 필요한 양보다 더 많은 양의 데이터를 요청하게 될 수도 있다.
이러한 것들을 백엔드 개발자가 주시하고 캐치함으로써 어떠한 일이 일어나고 있는지 잘 파악해야 한다. 참조
이러한 일들을 막기 위해서 백엔드 개발자는 너무 복잡한 쿼리, 악의적 쿼리등으로 시스템의 부하가 과중되는 일을 막아야 한다. 그러한 몇가지 전략에 대해서 조사해보았다.
시간 제한
가장 간단한 전략은 쿼리에 대해서 시간 제한을 두어 클라이언트로부터 전송받은 쿼리가 너무 오랜 기간동안 실행되지 않도록 처리하는 것이다.
시간 제한의 장점은 구현이 쉽다는 점이고, 단점으로써는 시간 제한에 의해서 실행이 멈추더라도 서버에 대한 피해를 돌이킬수 없고, 때로는 일정 시간이 흐른 뒤 통신을 끊는 것이 의도치 않은 동작을 유발할 수 있기 때문에 구현이 더 어려워 질 수 있다.
최대 쿼리 깊이
앞서 말했듯, gql을 사용하는 클라이언트는 그들이 원하는 복잡한 쿼리를 만들고 전송할 수 있따. gql 스키마는 순환 형태의 그래프를 가지고, 다음과 같은 쿼리 또한 만들 수 있다.
query IAmEvil {
author(id: "abc") {
posts {
author {
posts {
author {
posts {
author {
# that could go on as deep as the client wants!
}
}
}
}
}
}
}
}
이와 같은 쿼리를 반복해서 작성할 때 서버가 감당할 수 있는 깊이 이상으로 작성하고 실행시킬때, 서버에 과도한 부하가 생기게 된다. 이런 쿼리를 미리 방지하기 위해서, 쿼리의 추상 문법 트리(AST)를 분석하면 gql 서버는 들어온 쿼리의 깊이를 기반으로 실행을 허용하거나 거절할 수 있다.
이러한 방식의 장점은 쿼리가 정적으로 분석되기 때문에 실행이 이루어지기 이전에 실행과 거절의 판단이 이루어지고, gql서버에 생기는 부담이 발생하지 않는다. 하지만 깊이라는 값 자체로는 악의적인 쿼리를 가려내기 충분하지 않은 정보이다.
쿼리복잡도
쿼리 깊이만으로는 gql쿼리의 크기 또는 비용을 가늠하기 힘들다. 깊이가 깊은 쿼리가 있을 수 있는 것처럼, 최상위에서 지나치게 큰 크기의 노드에 대한 요청을 보낸 쿼리는 비싼 요청이지만 쿼리 깊이 분석으로는 차단되지 않는다. 이럴 경우에 쿼리 필드에 복잡도를 부여하고 계산하는 방법으로써 요청받은 쿼리가 얼마나 복잡한지에 대해서 계산하게 된다.
query {
author(id: "abc") { # 복잡도: 1
posts(first: 5) { # 복잡도: 5
title # 복잡도: 1
}
}
}
위의 쿼리를 볼 때에, 각 필드의 기본 복잡도는 1로써 설정되고 posts에서 인자값에 따라 복잡도가 추가적으로 설정되게 된다. 이 경우 쿼리의 복잡도는 7 로써, 이를 바탕으로 쿼리를 실행할지 말지를 결정 할 수 있게 된다.
이러한 방식은 쿼리 깊이에 비하여 더 많은 경우를 다룰 수 있고, 이를 통해 조금 더 유연하게 쿼리를 판단할 수 있게 된다.
하지만 이 방법은 완벽하게 구현하는 것이 어렵고, 뮤테이션 같은 경우 복잡도를 측정하기 어렵다. 이러한 경우에 어떻게 다룰 것인지 미리 설정해야 한다.
쓰로틀링
위의 방법들은 단일의 큰 쿼리를 분석하고 실행할지 말지에 대해 판단할 때 유용하다. 하지만 이를 나눠서 여러개의 쿼리로 보낼때, 서버는 이러한 형태의 악의적 쿼리로 인해 서버 자원이 낭비되게 된다. 이럴때 클라이언트별로 일정기간동안, 일정한 양 만큼의 실행된 쿼리들의 쿼리 복잡도를 계산하여 추가적인 쿼리를 받을지 말지를 계산할 수 있게 된다.
이러한 값들로 클라이언트로부터 추가적으로 받은 쿼리를 실행할지 말지를 결정하는 알고리즘으로는 Leaky Bucket 알고리즘이 있다링크. 해당 링크의 이미지처럼, 분당 총합 50이라는 복잡도의 합을 클라이언트에 부여할 때 각 클라이언트로부터 전송받은 쿼리들의 복잡도 합이 50이 넘어갈 경우 양동이의 아래로 물이 빠지는 것처럼 양동이의 물이 빠질때까지 추가적인 쿼리들을 무시하는 방식으로 구현할 수 있을 것이다. 이 방법을 채용할 경우, 백엔드 개발자는 클라이언트에게 얼마만큼의 허용량을 부여할 수 있을지 알려주기 편하고, 클라이언트도 전송 전 자신이 보내는 쿼리에 대해서 분석하고 제한을 설정할 수 있을 것이다.
gql이 작동하는 방식
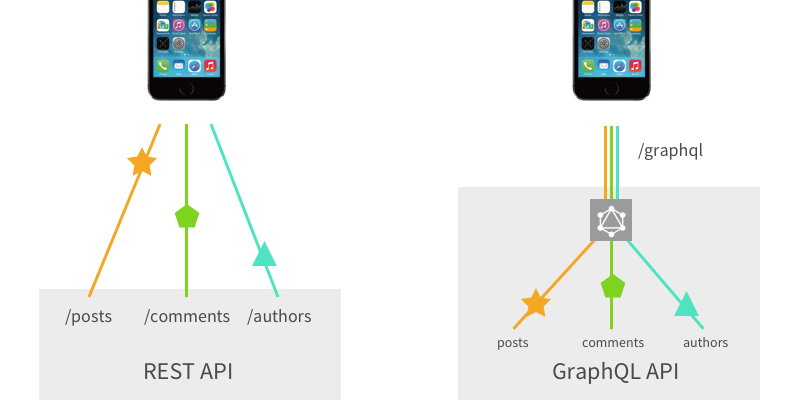
출처
해당 이미지에서는 모바일 기기 즉 클라이언트와 gql 서버, rest api 서버와 통신하는 모습을 대조적으로 보여주고 있다. 이 사진에서 조금 더 파고들어가면,
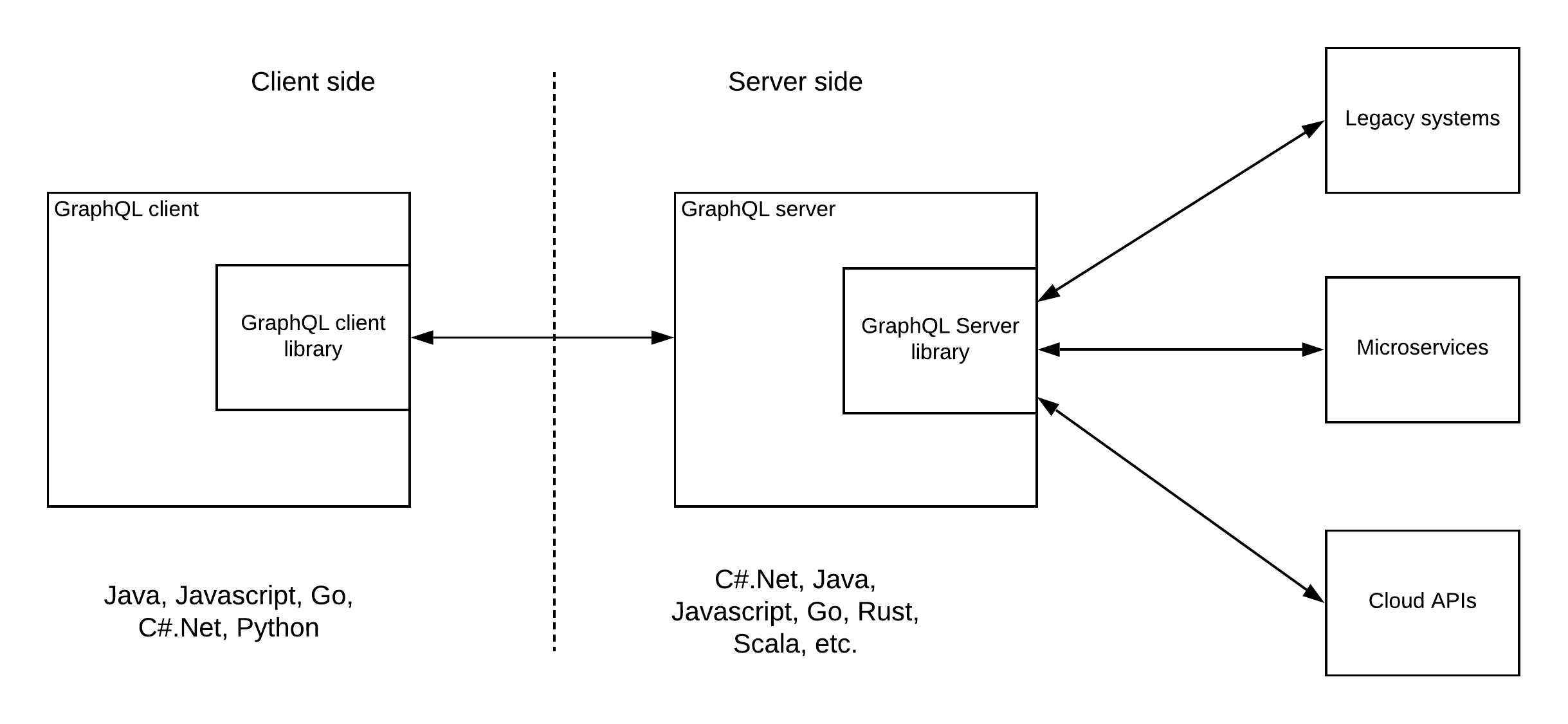
출처
이러한 다이어그램도 있을 것이다. 결국 클라이언트가 보내주는 쿼리에 대해서 분석하고, 그 쿼리에 합당한 값을 어디서 구할지 설정된 스키마에서 찾고, 그 값을 찾을수 있는 소스를 적절한 시스템, 데이터베이스, 타 api들, 기존에 사용하던 rest api등등에서 끌고와 하나의 데이터로 만들어 보내주는 역할인 것이다.
그렇기 때문에 시스템 내의 데이터베이스 뿐만 아니라, 타 api나 정말 온갖 리소스에서 데이터를 끌고올 수 있고, 기존에 운용하던 REST api에서 데이터를 끌고 올 수 있다.
물론 기존에 사용하던 REST api에 대해서 서비스단위로 파일을 잘 분리해 놨다면 gql서버로 이식하는데 큰 어려움이 있진 않겠지만…
여하튼 위 사진의 출처로 들어가게 된다면 다이어그램을 통해 많은 리소스들이 붙을 수 있고, 또 보안, 쓰로틀링, 모니터링 기능을 수행하는 api 게이트웨이를 붙일 수 있도 있음을 보여준다.
결론
현재 진행하는 Nest 프로젝트에서 gql을 적용하기 이전에 기존 REST api부터 잘 개발해놓고, 이후 gql을 적용하는 방식으로 진행하더라도 크게 상관은 없을것 같다.
나중에 머리 복잡해지기 싫다면 한번 코드 짤때 컨트롤러와 서비스단 등을 잘 구분해 놔야겠다는 생각도 들고, 이러한 것은 gql이 아니더라도 나중에 유지보수 할 때도 좋게 작용하지 않을까 하는 생각이 든다.