큰일났다. 지금 진행중인 프로젝트에서 매일의 전국 날씨에 대한 데이터를 수집해서 데이터에 저장하고 있는데, 이게 며칠만 지나버리니까 내 생각보다 더 많은 데이터가 쌓이고 있다.
잠시 골골거리고 왔더니, 대충 800만개 정도의 데이터가 쌓여있었고, 한 지역의 특정 날짜 날씨 데이터를 검색하는데 7초 정도 소요되었다.
이정도면 실 서비스 들어갔을때 진짜 얼마나 큰 욕을 먹으려고…
그래서 성능 개선을 시킬 수 있는 방법 중에 데이터베이스가 올라가 있는 서버의 성능 자체를 업그레이드 시키는 방법과, 데이터베이스 개선을 통해서 쿼리 실행 속도를 개선하는 방법이 있는걸 확인했다.
가난한 학생의 돈으로 서버에 큰 돈을 들일수도 없고.. 지금 서버로 사용하는 사양도 실행 서비스 대비 나쁜건 아니라고 생각한다(사용자도 나 하나 뿐인데)
user@violet:~$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 2
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 21
Model: 19
Model name: AMD A4-4020 APU with Radeon(tm) HD Graphics
Stepping: 1
CPU MHz: 1558.838
CPU max MHz: 3200.0000
CPU min MHz: 1400.0000
BogoMIPS: 6387.97
Virtualization: AMD-V
L1d cache: 16K
L1i cache: 64K
L2 cache: 1024K
NUMA node0 CPU(s): 0,1
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 popcnt aes xsave avx f16c lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs xop skinit wdt lwp fma4 tce nodeid_msr tbm topoext perfctr_core perfctr_nb cpb hw_pstate ssbd vmmcall bmi1 arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold
user@violet:~$ free
total used free shared buff/cache available
Mem: 7072480 3185332 718108 39636 3169040 3546544
Swap: 1000444 51968 948476
혼자 쓰는데 2코어 2스레드에 메모리 8기가면 투자 많이 했지…
그래서 하드웨어는 그대로 두고, 데이터베이스 개선을 통해서 어떻게 속도를 끌어올릴지 생각하게 되었다.
그 중에 가장 빠르게 효과를 볼 수 있는 방법으로 인덱싱을 찾게 되었고, 검색에 사용하는 컬럼에 대해서 인덱싱 처리로 인해서 0.초 대로 쿼리 실행을 마칠 수 있도록 하였다!
데이터 베이스 현황
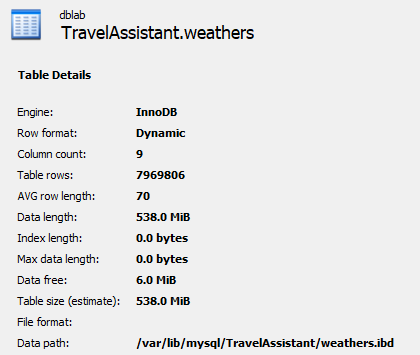
지금 디비의 상태는 약 790만 건의 데이터가 저장되어 있는 상태고, 인덱싱은 인덱스 컬럼 하나에 대해서만 되어 있다.
CREATE TABLE `weathers` (
`weathers_idx` int NOT NULL AUTO_INCREMENT,
`base_date` varchar(10) DEFAULT NULL,
`base_time` varchar(10) DEFAULT NULL,
`category` varchar(4) DEFAULT NULL COMMENT,
`fcst_date` varchar(10) DEFAULT NULL,
`fcst_time` varchar(10) DEFAULT NULL,
`fcst_value` varchar(10) DEFAULT NULL,
`nx` int DEFAULT NULL,
`ny` int DEFAULT NULL,
PRIMARY KEY (`weathers_idx`)
) ENGINE=InnoDB AUTO_INCREMENT=13828091 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
데이터베이스 ddl은 기본적으로 이러한 모양이였다. 지금 보니 idx가 천만대까지 상승을 했네…
 실행시간은 7.5초로, 요청이 들어오고 서버에서 디비에 쿼리 날리고, 데이터 받아오고, 처리한 후 다시 클라이언트에 전송되기까지
클라이언트 입장에서는 매우매우매우 긴 시간이다.
실행시간은 7.5초로, 요청이 들어오고 서버에서 디비에 쿼리 날리고, 데이터 받아오고, 처리한 후 다시 클라이언트에 전송되기까지
클라이언트 입장에서는 매우매우매우 긴 시간이다.
거기다가 사용자가 나 혼자만이 아니라 여러 사람이 몰려서 사용한다? 서비스가 당장이라도 안 다운되는게 이상한 정도…
이 문제의 디비에 대해서 조금의 수정을 가해보자.
인덱싱 걸기
인덱싱을 걸기 전에 주의해야 할 몇가지 특이사항들이 있다.
- 무조건 많이 설정하지 않는다. (한 테이블당 3~5개가 적당 목적에 따라 상이)
- 조회시 자주 사용하는 컬럼
- 고유한 값 위주로 설계
- 카디널리티가 높을 수록 좋다 (= 한 컬럼이 갖고 있는 중복의 정도가 낮을 수록 좋다.)
- INDEX 키의 크기는 되도록 작게 설계
- PK, JOIN의 연결고리가 되는 컬럼
- 단일 인덱스 여러 개 보다 다중 컬럼 INDEX 생성 고려
- UPDATE가 빈번하지 않은 컬럼
- JOIN시 자주 사용하는 컬럼
- INDEX를 생성할 때 가장 효율적인 자료형은 정수형 자료(가변적 데이터는 비효율적) 출처
여기서 내가 가장 크게 유의해야 할 것은, 너무 많은 인덱싱을 걸지 않고, 조회시 자주 사용하는 컬럼, 카디널리티 고려, 정수형 자료에 대한 인덱싱이다. 조인과 외래키는 사용하지 않기 때문에 신경쓰지 않을 것이고, 처음은 단일 인덱스 3개로, 이후 익숙해지면 다중 컬럼 인텍스까지 시도해 볼 예정이라 여기서는 제외했다.
그렇게 고려하여 3개의 컬럼에 대해서 인덱싱에 인덱스를 걸어 보았다.
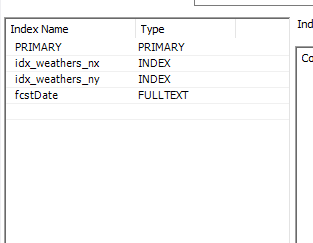
이렇게 idx를 포함한 총 3개의 인덱싱이 걸렸고, 결과를 살펴보자.
 와! 실행시간이 단 0.2초!
와! 실행시간이 단 0.2초!
조금 더 빨랐으면 하는 바람이 있지만, 단순히 인덱스만 걸었는데 이정도의 속도까지 끌어올릴 수 있었다는 것에 대해…서 만족하기보다는 조금만 더 만져보자
테이블 컬럼 수정
기존의 데이터베이스에서는 날짜, 시간이 모두 가변형 텍스트로 들어가 있는 문제점이 있다. 이러한 점은 위의 고려사항에서 가변형 데이터는 비효율적이라는 점에 대해서 위반사유이기 때문에, 1차적으로는 테이블에 수정이 들어가야하고, 2차적으로는 서버에서 돌아가는 엔티티와 해당 서비스 레이어에서 수정이 다시 들어가야한다.
우선 변경한 테이블의 ddl이다.
CREATE TABLE `weathers_converted` (
`weather_idx` int NOT NULL AUTO_INCREMENT,
`base_date` date DEFAULT NULL,
`base_time` time DEFAULT NULL,
`category` varchar(4) DEFAULT NULL,
`fcst_date` date DEFAULT NULL,
`fcst_time` time DEFAULT NULL,
`fcst_value` varchar(10) DEFAULT NULL,
`nx` int DEFAULT NULL,
`ny` int DEFAULT NULL,
`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`deleted_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`weather_idx`),
) ENGINE=InnoDB AUTO_INCREMENT=151284 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
mysql에서 제공하는 데이터 형식으로 바꿀 수 있는 값들은 전부 변경했고, created_at 과 updated_at, deleted_at을 추가했다. created_at으로부터 1주일이 지난 데이터는 deleted_at으로 일괄 삭제(timestamp값 넣기)를 걸고, 검색하는 쿼리에 deleted_at = NULL을 추가해준다.
이 방식으로 개선했을때 쿼리 속도가 0.1초가 찍히긴 했는데… 일단 아직 추가된 데이터도 많이 없고 이전의 데이터처럼 백만건 단위로 쌓이지 않았기 때문에, 우선은 이렇게 며칠간 더 돌려봐야겠다. 이후에 데이터가 더 쌓인다면, 지금과 같은 속도가 나올수 있을지 확인해보는 시간을 가져봐야겠다!